We use cookies to enhance the usability of our website. If you continue, we'll assume that you are happy to receive all cookies. More information. Don't show this again.
RNA category is based on mRNA expression levels in the analyzed samples (RNA assay description). The categories include: tissue enriched, group enriched, tissue enhanced, expressed in all, mixed and not detected. RNA category is calculated separately for data imported from The Genotype-Tissue Expression project (GTEX), FANTOM5 Consortium (FANTOM5) and internally generated Human Protein Atlas (HPA) data.
Protein evidence scores are generated from several independent sources and are classified as evidence at i) protein level, ii) transcript level, iii) no evidence, or iv) not available.
Evidence at protein level
Protein expressioni
A summary of the overall protein expression pattern across the analyzed normal tissues. The summary is based on knowledge-based annotation.
"Estimation of protein expression could not be performed. View primary data." is shown for genes analyzed with a knowledge-based approach where available RNA-seq and gene/protein characterization data has been evaluated as not sufficient in combination with immunohistochemistry data to yield a reliable estimation of the protein expression profile.
Standardized explanatory sentences with additional information required for full understanding of the knowledge-based expression profile.
Pending external verification.
Reliability scorei
Reliability score (score description), divided into Enhanced, Supported, Approved, or Uncertain, is evaluated in normal tissues and based on consistency between antibody staining pattern, available RNA-Seq and gene/protein characterization data, as well as similarity between independent antibodies targeting the same protein.
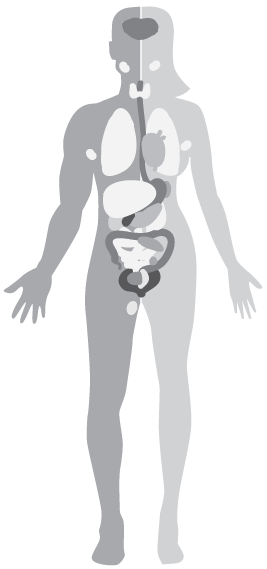
Below is an overview of RNA and protein expression data generated in the Human Protein Atlas project. Analyzed tissues are divided into color-coded groups according to which functional features they have in common. For each group, a list of included tissues is accessed by clicking on group name, group symbol, RNA bar, or protein bar. Subsequent selection of a particular tissue in this list links to the image data page.
Images of selected tissues give a visual summary of the protein expression profile furthest to the right.
The gray human body provides links to a histology dictionary when clicking on any part of the figure.
RNA expression (TPM)i
RNA-seq results generated in HPA are reported as number of transcripts per million (TPM). Each bar represents the highest expression score found in a particular group of tissues. The assay is described more in detail in Assays & Annotation.
Protein expression (score)i
Each bar represents the highest expression score found in a particular group of tissues. Protein expression scores are based on a best estimate of the "true" protein expression from a knowledge-based annotation, described more in detail under Assays & annotation. For genes where more than one antibody has been used, a collective score is set displaying the estimated true protein expression.
Protein expression data is shown for each of the 44 tissues. Color-coding is based on tissue groups, each consisting of tissues with functional features in common. Mouse-over function shows protein score for analyzed cell types in a selected tissue. To access image data click on tissue name or bar. Annotation of protein expression is described in detail in Assays & annotation.
For genes with available protein data for which a knowledge-based annotation gave inconclusive results, no protein expression data is displayed in the protein expression data overview. However, all immunohistochemical images are still available and the annotation data can be found under Primary data.
Organ
Expression
Alphabetical
RNA EXPRESSION OVERVIEWi
RNA expression overview shows RNA-data from three different sources: Internally generated Human Protein Atlas (HPA) RNA-seq data, RNA-seq data from the Genotype-Tissue Expression (GTEx) project and CAGE data from FANTOM5 project. Color-coding is based on tissue groups, each consisting of tissues with functional features in common. To access sample data, click on tissue name or bar.
HPA dataseti
HPA dataset RNA-seq tissue data is reported as mean TPM (transcripts per million), corresponding to mean values of the different individual samples from each tissue. Color-coding is based on tissue groups, each consisting of tissues with functional features in common. To access sample data, click on tissue name or bar. The RNA-seq assay is described in detail in Assays & Annotation.
RNA tissue category HPA HPA RNA tissue category (category description) is calculated based on mRNA expression levels across all tissues and include: tissue enriched, group enriched, tissue enhanced, expressed in all, mixed and not detected.
Organ
Expression
Alphabetical
RNA tissue category: Expressed in all
GTEx dataseti
GTEx dataset RNA-seq data is reported as median RPKM (reads per kilobase per million mapped reads), generated by the Genotype-Tissue Expression (GTEx) project. More information can be found in Assays & Annotation.
RNA tissue category GTEx GTEx RNA tissue category (category description) is calculated based on mRNA expression levels across all tissues and include: tissue enriched, group enriched, tissue enhanced, expressed in all, mixed and not detected.
Organ
Expression
Alphabetical
RNA tissue category: Expressed in all
FANTOM5 dataseti
FANTOM5 dataset Tissue data obtained through Cap Analysis of Gene Expression (CAGE) are reported as Tags Per Million, generated by the FANTOM5 project. More information can be found in Assays & Annotation.
RNA tissue category FANTOM5 FANTOM5 RNA tissue category (category description) is calculated based on gene expression levels across all tissues and include: tissue enriched, group enriched, tissue enhanced, expressed in all, mixed and not detected.
Organ
Expression
Alphabetical
RNA tissue category: Expressed in all
GENE INFORMATIONi
Gene information from Ensembl and Entrez, as well as links to available gene identifiers are displayed here. Information was retrieved from Ensembl if not indicated otherwise.
Gene name
FAM177A1 (HGNC Symbol)
Synonyms
C14orf24
Description
Family with sequence similarity 177 member A1 (HGNC Symbol)
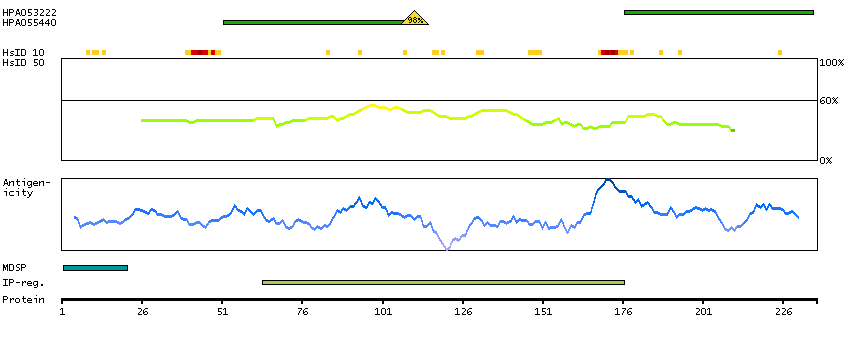
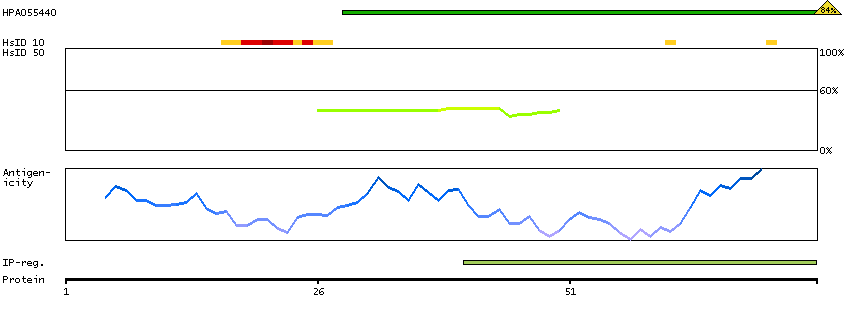
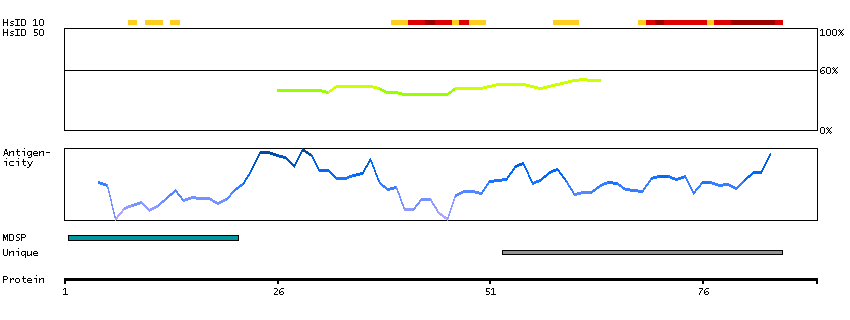
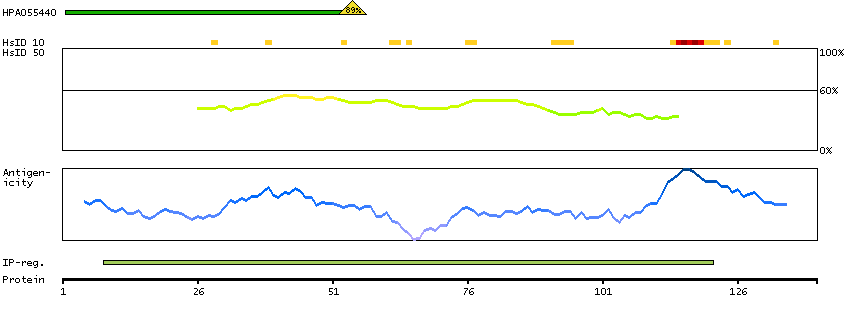
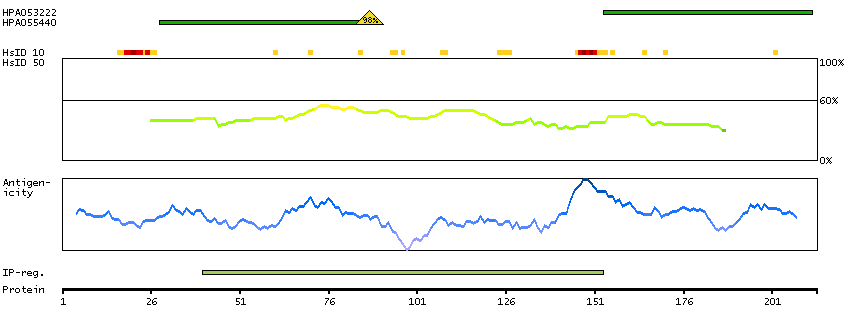
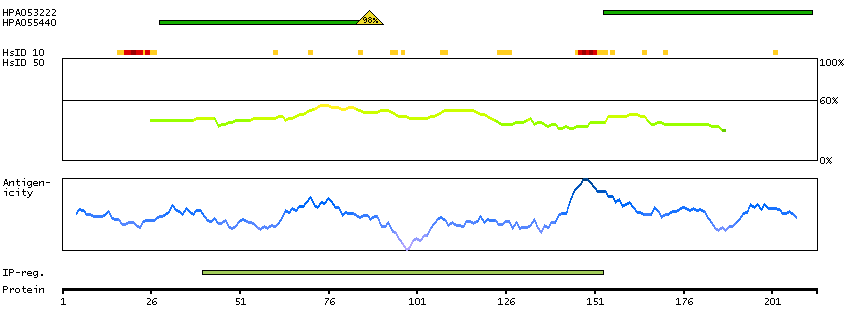
The protein browser displays the antigen location on the target protein(s) and the features of the target protein. The tabs at the top of the protein view section can be used to switch between the different splice variants to which an antigen has been mapped.
At the top of the view, the position of the antigen (identified by the corresponding HPA identifier) is shown as a green bar. A yellow triangle on the bar indicates a <100% sequence identity to the protein target.
Under the antigens, the maximum percent sequence identity of the protein to all other proteins from other human genes is displayed, using a sliding window of 10 aa residues (HsID 10) or 50 aa residues (HsID 50). The region with the lowest possible identity is always selected for antigen design, with a maximum identity of 60% allowed for designing a single-target antigen (read more).
The curve in blue displays the predicted antigenicity i.e. the tendency for different regions of the protein to generate an immune response, with peak regions being predicted to be more antigenic.The curve shows average values based on a sliding window approach using an in-house propensity scale. (read more).
If a signal peptide is predicted by a majority of the signal peptide predictors SPOCTOPUS, SignalP 4.0, and Phobius (turquoise) and/or transmembrane regions (orange) are predicted by MDM, these are displayed.
Low complexity regions are shown in yellow and InterPro regions in green. Common (purple) and unique (grey) regions between different splice variants of the gene are also displayed (read more), and at the bottom of the protein view is the protein scale.
FAM177A1-001
FAM177A1-002
FAM177A1-003
FAM177A1-007
FAM177A1-010
FAM177A1-201
PROTEIN INFORMATIONi
The protein information section displays alternative protein-coding transcripts (splice variants) encoded by this gene according to the Ensembl database.
The ENSP identifier links to the Ensembl website protein summary, while the ENST identifier links to the Ensembl website transcript summary for the selected splice variant. The data in the UniProt column can be expanded to show links to all matching UniProt identifiers for this protein.
The protein classes assigned to this protein are shown if expanding the data in the protein class column. Parent protein classes are in bold font and subclasses are listed under the parent class.
The Gene Ontology terms assigned to this protein are listed if expanding the Gene ontology column. The length of the protein (amino acid residues according to Ensembl), molecular mass (kDalton), predicted signal peptide (according to a majority of the signal peptide predictors SPOCTOPUS, SignalP 4.0, and Phobius) and the number of predicted transmembrane region(s) (according to MDM) are also reported.
Predicted secreted proteins Secreted proteins predicted by MDSEC SignalP predicted secreted proteins Phobius predicted secreted proteins SPOCTOPUS predicted secreted proteins Protein evidence (Kim et al 2014) Protein evidence (Ezkurdia et al 2014)
 The Human Protein Atlas project is funded
The Human Protein Atlas project is funded



 MENU
MENU