We use cookies to enhance the usability of our website. If you continue, we'll assume that you are happy to receive all cookies. More information. Don't show this again.
Show complete data for human cells assay. The location(s) are highlighted in the illustration on the right.
RNA cell categoryi
The cell lines in the Human Protein Atlas have been analyzed by RNA-seq to estimate the transcript abundance of each protein-coding gene. The RNA-seq data was then used to classify all genes according to their cell line-specific expression into one of six different categories, defined based on the total set of all TPM values in all analyzed cell lines.
Protein evidence scores are generated from several independent sources and are classified as evidence at i) protein level, ii) transcript level, iii) no evidence, or iv) not available.
Evidence at protein level
Main locationi
The main location is characterized by presence in all tested cell lines and/or increased intensity compared to other locations. It is highlighted in the illustration to the right. If available, links to overrepresentation analyses in Reactome, a free, open-source, curated and peer reviewed biological pathway database, are provided. An analysis is done for the corresponding gene set of the proteome localizing to the main and additional locations of the protein on this page, respectively.
Not available
DATA RELIABILITY
Reliability scorei
A reliability score is set for all genes and indicates the level of reliability of the analyzed protein expression pattern based on available protein/RNA/gene characterization data. The reliability of the annotated protein expression data is also scored depending on similarity in immunostaining patterns and consistency with available experimental gene/protein characterization data in the UniProtKB/Swiss-Prot database.
Below is an overview of RNA expression data generated in the HPA project. The analyzed cell lines are divided into 12 color-coded groups according to the organ they were obtained from. By clicking the toolbars in the top right corner it is possible to sort the cell lines in the chart by different criteria: the organ and the origin that the cell line was obtained from, the category of the cell line according to cellosaurus, alphabetically or by descending RNA expression. Detailed information about a specific cell line can be accessed by hovering over the corresponding bar in the chart. The RNA-sequencing results generated in the HPA are reported as number of Transcripts per Kilobase Million (TPM). In the Human Protein Atlas a TPM value of 1.0 is defined as a treshhold for expression of the corresponding protein.
The cell lines in the Human Protein Atlas have been analyzed by RNA-seq to estimate the transcript abundance of each protein-coding gene. The RNA-seq data was then used to classify all genes according to their cell line-specific expression into one of six different categories, defined based on the total set of all TPM values in all analyzed cell lines.
Cell lines sorted after organ of phenotypic resemblance.
Cell lines sorted after biological source for establishment.
Cell lines sorted after the cell line category according to Cellosaurus.
Cell lines sorted on descending RNA expression.
Cell lines sorted alphabetically.
GENE INFORMATIONi
Gene information from Ensembl and Entrez, as well as links to available gene identifiers are displayed here. Information was retrieved from Ensembl if not indicated otherwise.
Gene name
CD5 (HGNC Symbol)
Synonyms
LEU1, T1
Description
CD5 molecule (HGNC Symbol)
Entrez gene summary
This gene encodes a member of the scavenger receptor cysteine-rich (SRCR) superfamily. Members of this family are secreted or membrane-anchored proteins mainly found in cells associated with the immune system. This protein is a type-I transmembrane glycoprotein found on the surface of thymocytes, T lymphocytes and a subset of B lymphocytes. The encoded protein contains three SRCR domains and may act as a receptor to regulate T-cell proliferation. Alternative splicing results in multiple transcript variants encoding different isoforms. [provided by RefSeq, Oct 2016]
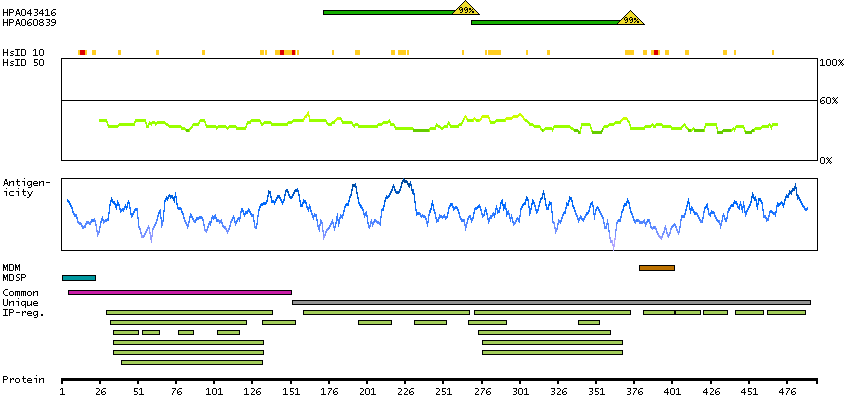
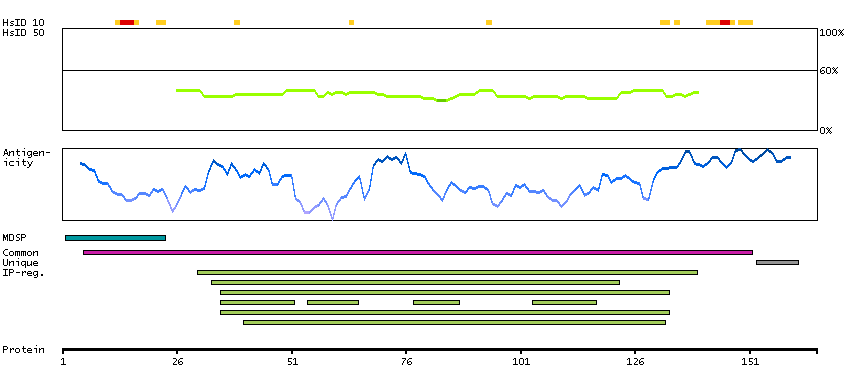
The protein browser displays the antigen location on the target protein(s) and the features of the target protein. The tabs at the top of the protein view section can be used to switch between the different splice variants to which an antigen has been mapped.
At the top of the view, the position of the antigen (identified by the corresponding HPA identifier) is shown as a green bar. A yellow triangle on the bar indicates a <100% sequence identity to the protein target.
Under the antigens, the maximum percent sequence identity of the protein to all other proteins from other human genes is displayed, using a sliding window of 10 aa residues (HsID 10) or 50 aa residues (HsID 50). The region with the lowest possible identity is always selected for antigen design, with a maximum identity of 60% allowed for designing a single-target antigen (read more).
The curve in blue displays the predicted antigenicity i.e. the tendency for different regions of the protein to generate an immune response, with peak regions being predicted to be more antigenic.The curve shows average values based on a sliding window approach using an in-house propensity scale. (read more).
If a signal peptide is predicted by a majority of the signal peptide predictors SPOCTOPUS, SignalP 4.0, and Phobius (turquoise) and/or transmembrane regions (orange) are predicted by MDM, these are displayed.
Low complexity regions are shown in yellow and InterPro regions in green. Common (purple) and unique (grey) regions between different splice variants of the gene are also displayed (read more), and at the bottom of the protein view is the protein scale.
CD5-001
CD5-002
PROTEIN INFORMATIONi
The protein information section displays alternative protein-coding transcripts (splice variants) encoded by this gene according to the Ensembl database.
The ENSP identifier links to the Ensembl website protein summary, while the ENST identifier links to the Ensembl website transcript summary for the selected splice variant. The data in the UniProt column can be expanded to show links to all matching UniProt identifiers for this protein.
The protein classes assigned to this protein are shown if expanding the data in the protein class column. Parent protein classes are in bold font and subclasses are listed under the parent class.
The Gene Ontology terms assigned to this protein are listed if expanding the Gene ontology column. The length of the protein (amino acid residues according to Ensembl), molecular mass (kDalton), predicted signal peptide (according to a majority of the signal peptide predictors SPOCTOPUS, SignalP 4.0, and Phobius) and the number of predicted transmembrane region(s) (according to MDM) are also reported.
 The Human Protein Atlas project is funded
The Human Protein Atlas project is funded



 MENU
MENU