We use cookies to enhance the usability of our website. If you continue, we'll assume that you are happy to receive all cookies. More information. Don't show this again.
All assays through which the antibody has been validated. Assays&annotation provide a detailed description of the different assays. The pie-charts indicate degree of validation.
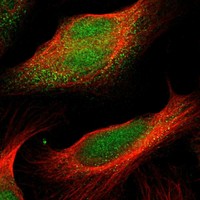
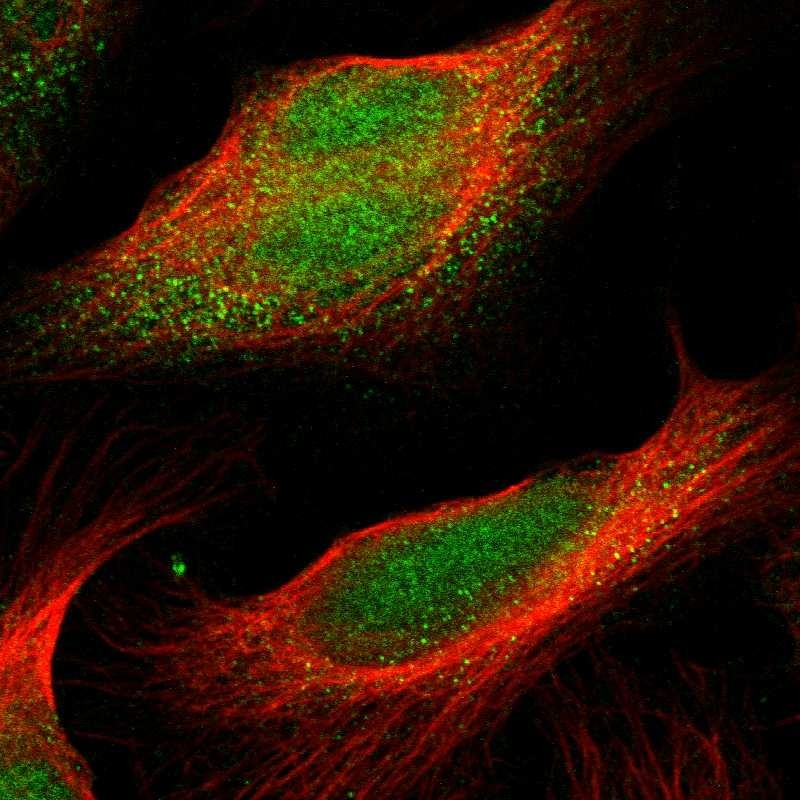
Immunocytochemistry is used to validate the antibody staining and for assessing and validating the protein expression pattern in selected human cell lines.
Results of validation by standard or enhanced validation.
Standard validation is based on concordance with available experimental gene/protein characterization data in the UniProtKB/Swiss-Prot database. Standard validation results in scores Supported, Approved or Uncertain.
Enhanced validation is performed using either siRNA knockdown, tagged GFP cell lines or independent antibodies. For the siRNA validation the decrease in antibody-based staining intensity upon target protein downregulation is evaluated. For the GFP validation the signal overlap between the antibody staining and the GFP-tagged protein is evaluated. For the independent antibodies validation the evaluation is based on comparison of the staining of two (or more) independent antibodies directed towards independent epitopes on the protein.
For all cases except the siRNA validation, an image representative of the antibody staining pattern is shown. For the siRNA validation, a box plot of the results is shown.
Location supported by experimental gene/protein characterization data and >=1 other antibody
Immunofluorescent staining of human cell line U-2 OS shows localization to nucleus & cytosol. Antibody dilution: 1:21
IMMUNOHISTOCHEMISTRYi
Immunohistochemistry is used for validating antibody reliability by assessing staining pattern in 44 normal tissues. Validation scores include Enhanced, Supported, Approved and Uncertain.
Results of validation by standard or enhanced validation based on assessment of antibody performance in 44 normal tissues.
Standard validation results in scores Supported, Approved or Uncertain. An image representative of the antibody staining pattern is shown.
Enhanced validation results in the score Enhanced and includes two methods: Orthogonal validation and Independent antibody validation. For orthogonal validation, representative images of high and low expression are shown. For independent antibody validation, four images of each independent antibody are displayed.
Immunohistochemistry is used for validating antibody reliability by assessing staining pattern in 44 normal tissues. Validation scores include Enhanced, Supported, Approved and Uncertain.
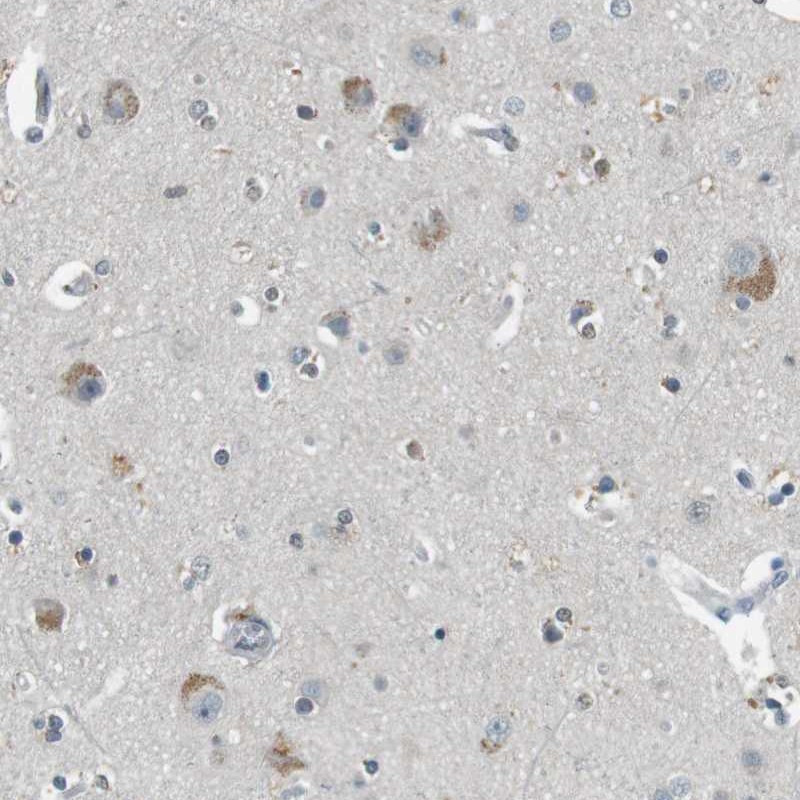
Immunohistochemical staining of human cerebral cortex shows cytoplasmic positivity in neuronal cells.
Retrieval
HIER pH6
Antibody dilution
1:20
Literature conformityi
Conformance of the expression pattern with available gene/protein characterization data in scientific literature and data from bioinformatic predictions. UniProt is used as the main source of gene/protein characterization data and when relevant, available publications and other sources of information are researched in depth. Extensive or sufficient gene/protein data requires that there is evidence of existence on a protein level and that a substantial quantity of published experimental data is available from literature and public databases. Limited protein/gene characterization data does not require evidence of existence on a protein level and refers to genes for which only bioinformatic predictions and scarce published experimental data is available.
Partly consistent with extensive gene/protein characterization data.
RNA consistencyi
Consistency between immunohistochemistry data and internally generated RNA-seq data is divided into five different categoreies: i) Consistent with RNA expression data, ii) Mainly consistent with RNA expression data, iii) Mainly not consistent with RNA expression data, iv) Not consistent with RNA expression data, and v) No internal RNA expression data available for correlation.
Mainly consistent with RNA expression data.
WESTERN BLOTi
A Western blot analysis is performed on a panel of human tissues and cell lines to evaluate antibody specificity. For antibodies with unreliable result a revalidation using an over-expression lysate is performed.
Western Blot is used for quality control of the polyclonal antibodies generated in the project. After purification, the antibodies are used to detect bands in a setup of lysate and different tissues. The result is then scored Enhanced, Supported, Approved, or Uncertain.
Enhanced validation includes five different methods: Genetic validation, Recombinant expression validation, Independent antibody validation, Orthogonal validation and Capture MS validation.
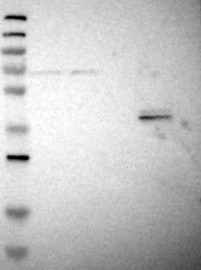
The staining of an antibody is evaluated by Western Blot through analysis of samples from different cell lysates. A supportive score is given if band(s) of predicted size in kDa (+/-20%) is detected.
Band of predicted size in kDa (+/-20%) with additional bands present. Analysis performed using a standard panel of samples.
230
130
95
72
56
36
28
17
11
Antibody dilution: 1:250
PROTEIN ARRAY
Validationi
A protein array containing 384 different antigens including the antibody target is used to analyse antibody specificity. Depending on the array interaction profile the antibody is scored as Supported, Approved, or Uncertain.
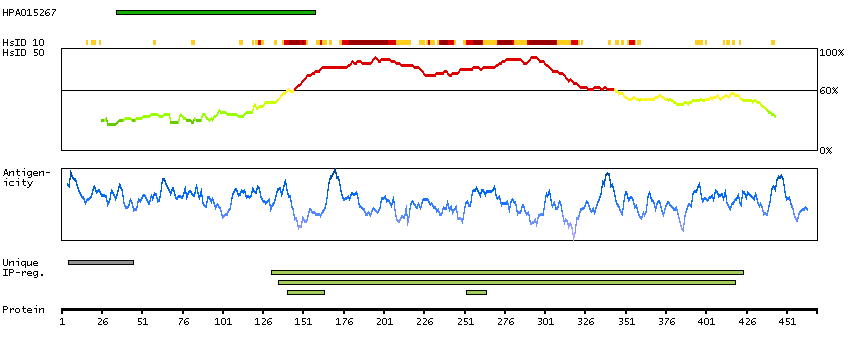
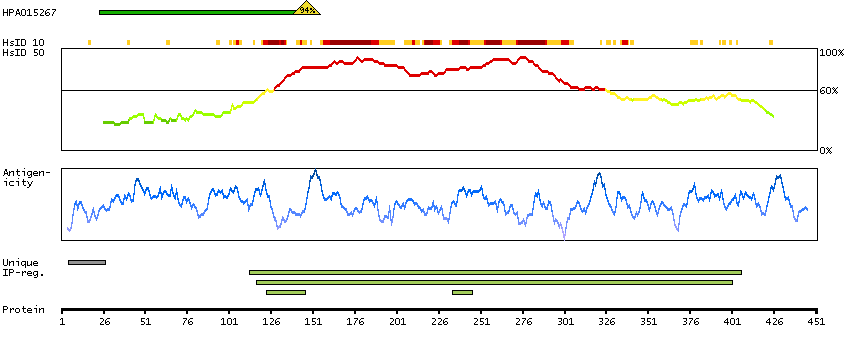
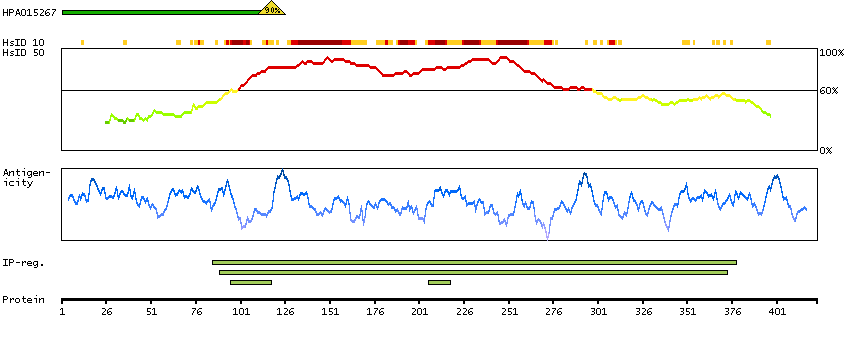
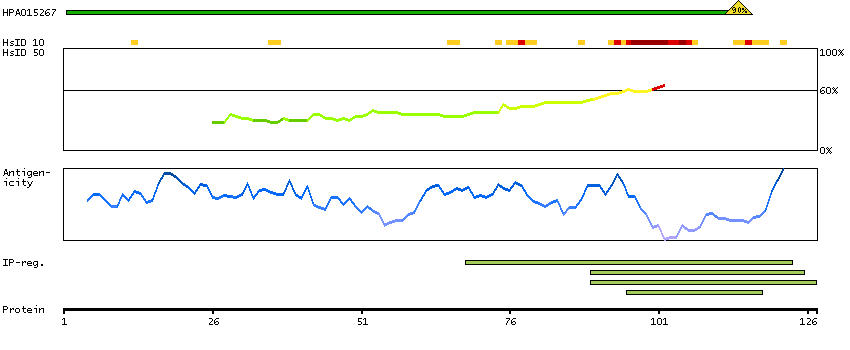
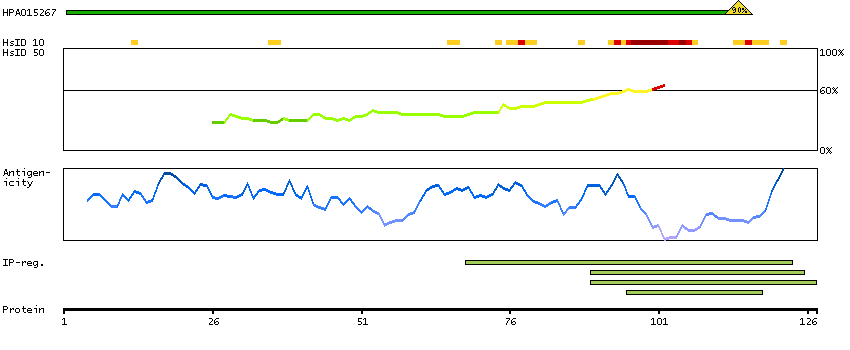
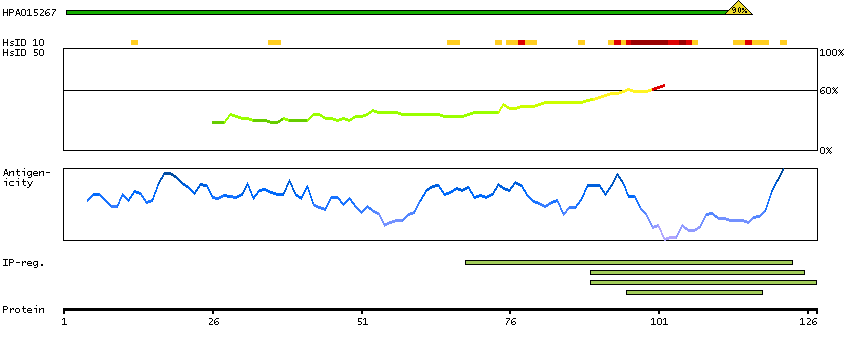
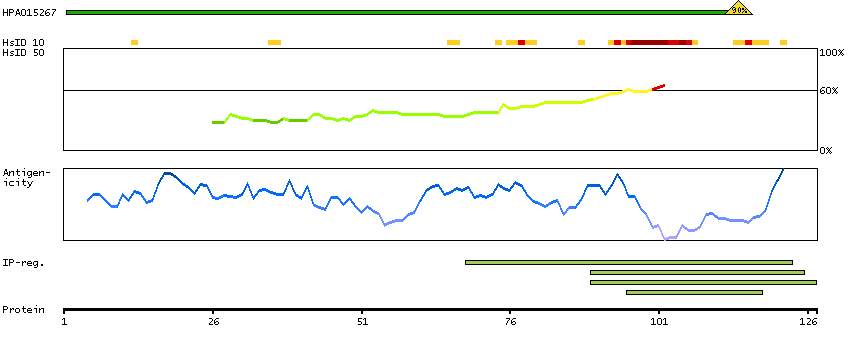
The protein browser displays the antigen location on the target protein(s) and the features of the target protein. The tabs at the top of the protein view section can be used to switch between the different splice variants to which an antigen has been mapped.
At the top of the view, the position of the antigen (identified by the corresponding HPA identifier) is shown as a green bar. A yellow triangle on the bar indicates a <100% sequence identity to the protein target.
Under the antigens, the maximum percent sequence identity of the protein to all other proteins from other human genes is displayed, using a sliding window of 10 aa residues (HsID 10) or 50 aa residues (HsID 50). The region with the lowest possible identity is always selected for antigen design, with a maximum identity of 60% allowed for designing a single-target antigen (read more).
The curve in blue displays the predicted antigenicity i.e. the tendency for different regions of the protein to generate an immune response, with peak regions being predicted to be more antigenic.The curve shows average values based on a sliding window approach using an in-house propensity scale. (read more).
If a signal peptide is predicted by a majority of the signal peptide predictors SPOCTOPUS, SignalP 4.0, and Phobius (turquoise) and/or transmembrane regions (orange) are predicted by MDM, these are displayed.
Low complexity regions are shown in yellow and InterPro regions in green. Common (purple) and unique (grey) regions between different splice variants of the gene are also displayed (read more), and at the bottom of the protein view is the protein scale.
 The Human Protein Atlas project is funded
The Human Protein Atlas project is funded



 MENU
MENU